Troubleshooting an ONNX Model deployment to Azure Functions
Navigate the deployment challenges of ML models to Azure Functions, from Python version mismatches to memory constraints. Discover how to use docker-based local builds with native dependencies to overcome remote build limitations.
Building awesome machine learning models can be an onerous task. Once all the blood, sweat and tears have been expended creating this magical (and ethical) model sometimes it feels like getting the thing deployed will require severing another limb in the name of releasing software. This post is designed to help you, dear reader, manage the land mines surrounding this complicated task and hopefully make this part of the development cycle painless.
Here's the rundown:
- I made a machine learning model in PyTorch that classifies tacos vs burrito images
- I exported the model to ONNX
- I want to deploy inferencing code to Azure Functions using Python
- I've been able to get the function running locally (this can be its own post but I thought the docs were excellent).
What follows is my journey getting this to work (with screenshots to boot). Let's dig in!
Running Locally
Once the Azure Function Core Tools are installed and you've pulled the code running things locally is very straightforward with this handy command:
func start
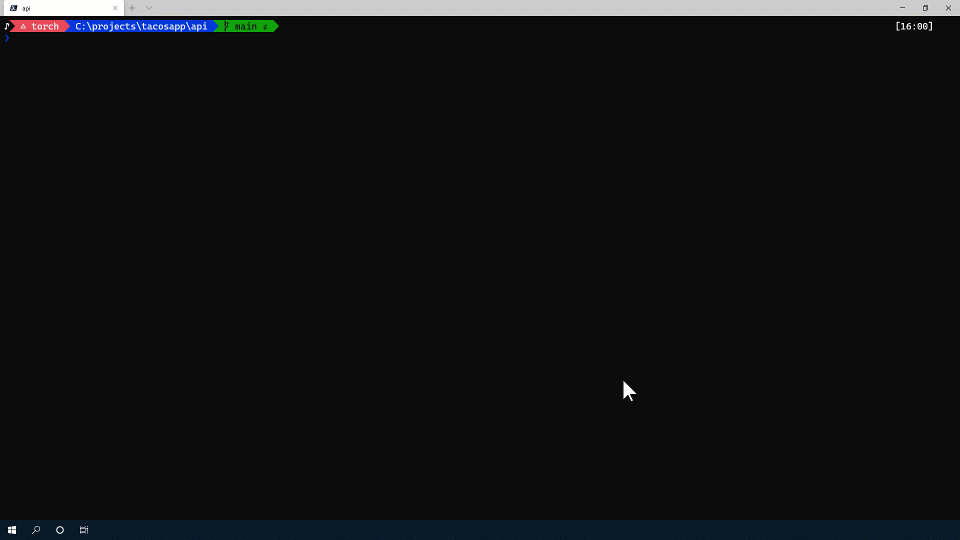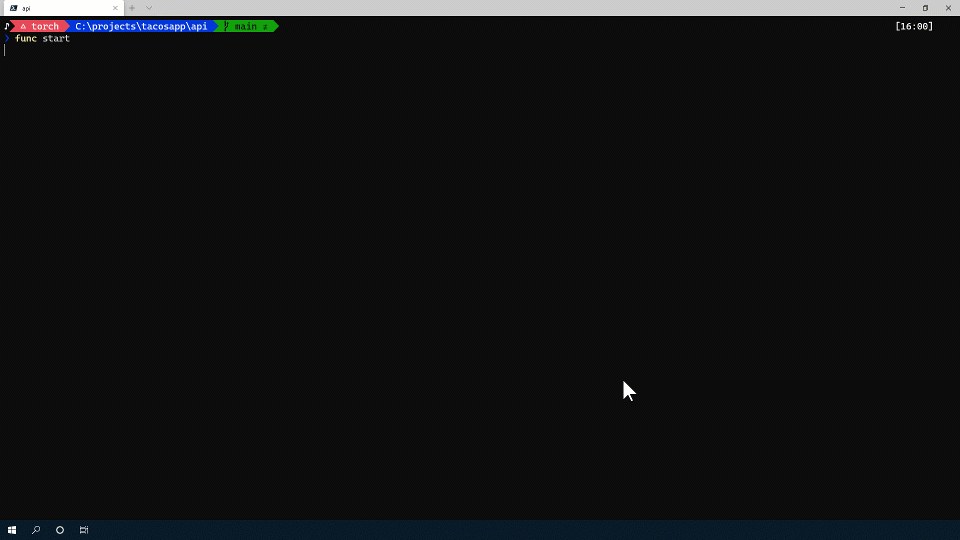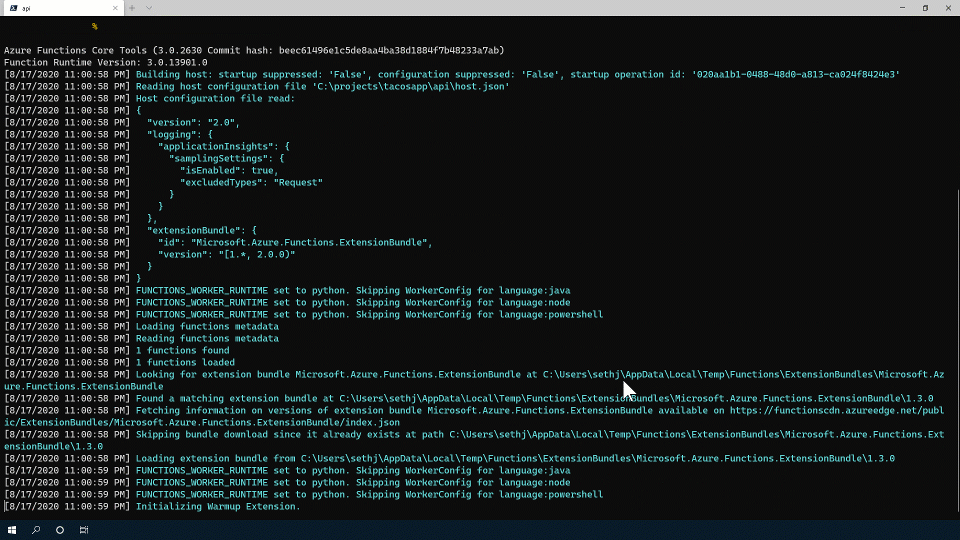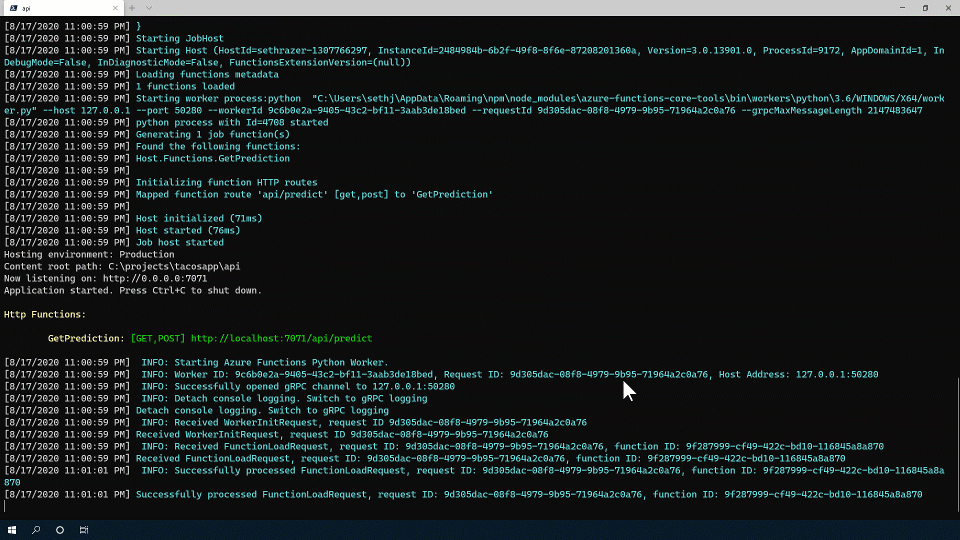
Notice that you get an endpoint that can easily be called to test everything out (I used a simple curl command to fire the function):
curl http://localhost:7071/api/predict?image=https://farm3.staticflickr.com/2302/2221460943_3c5c1846a5_z.jpg
The image parameter in the querystring tells the function which image to classify:

Creating the Function App
Here's the first thing that might trip you up (I made this mistake): make sure the Python version you developed the function with is the same one you use on the Function app.
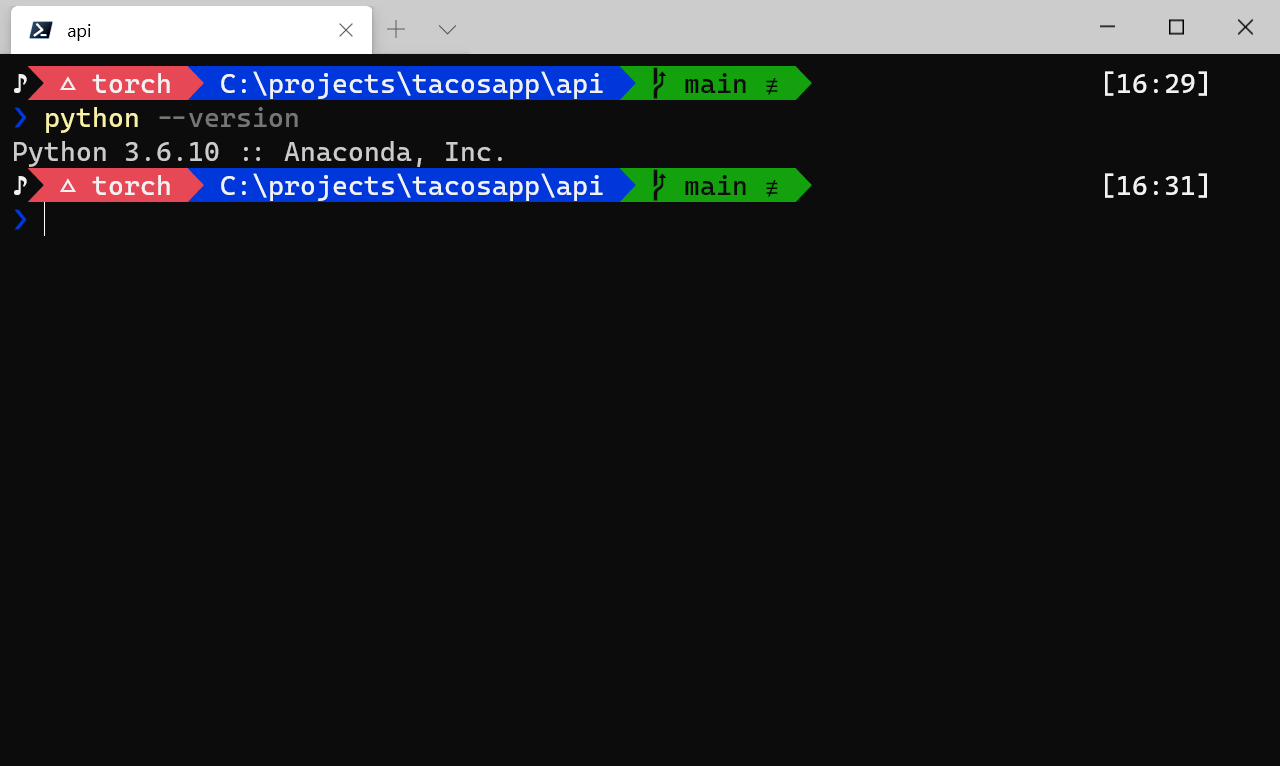
As you can see in this particular conda environment the Python version happens to be 3.6: it's basically what I used when I created the inferencing code. When you create your function app make sure to select the right version (turns out 3.6 is not the default - ask me later how I know):
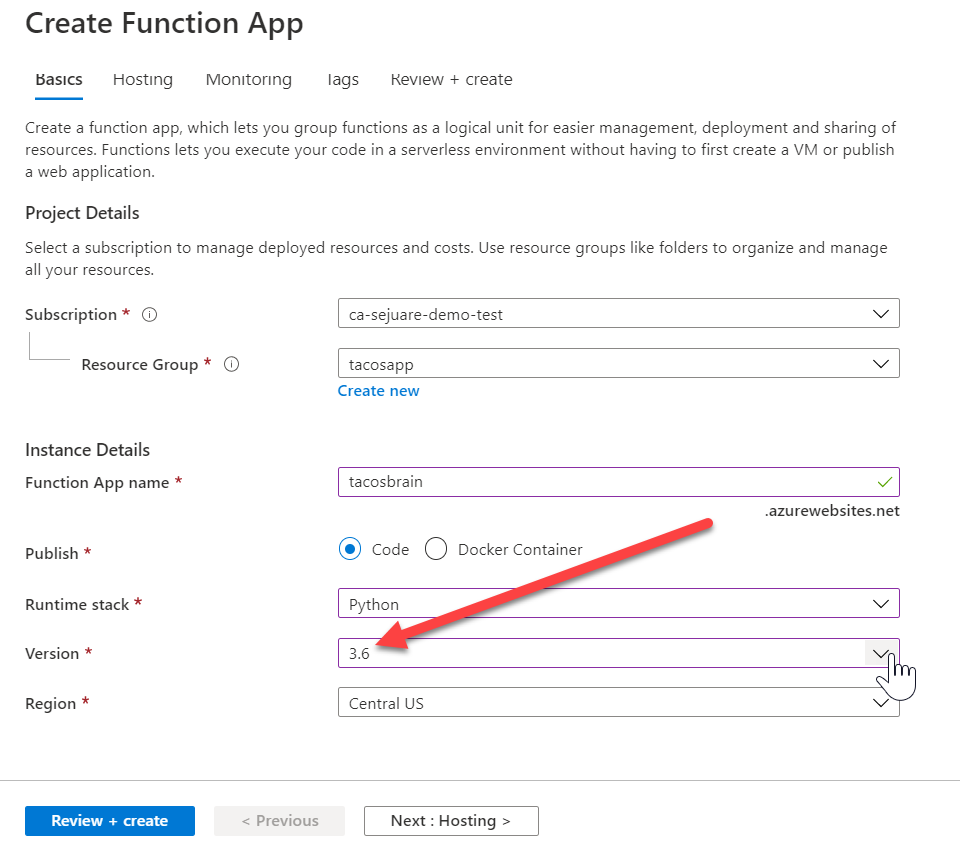
OK, it's later. I got the weirdest of errors with my mismatched Python versions that took forever to figure out.
Standard Deployment - Remote Build
There's a way to deploy function apps directly from Visual Studio Code. I decided to use the command line to show some of the issues you might run into.
Deploying the app is easily done with the following:
func azure functionapp publish tacosbrain
This initiates something called a remote build. It uploads your code and assets and attempts to build the Azure Function on a remote machine:
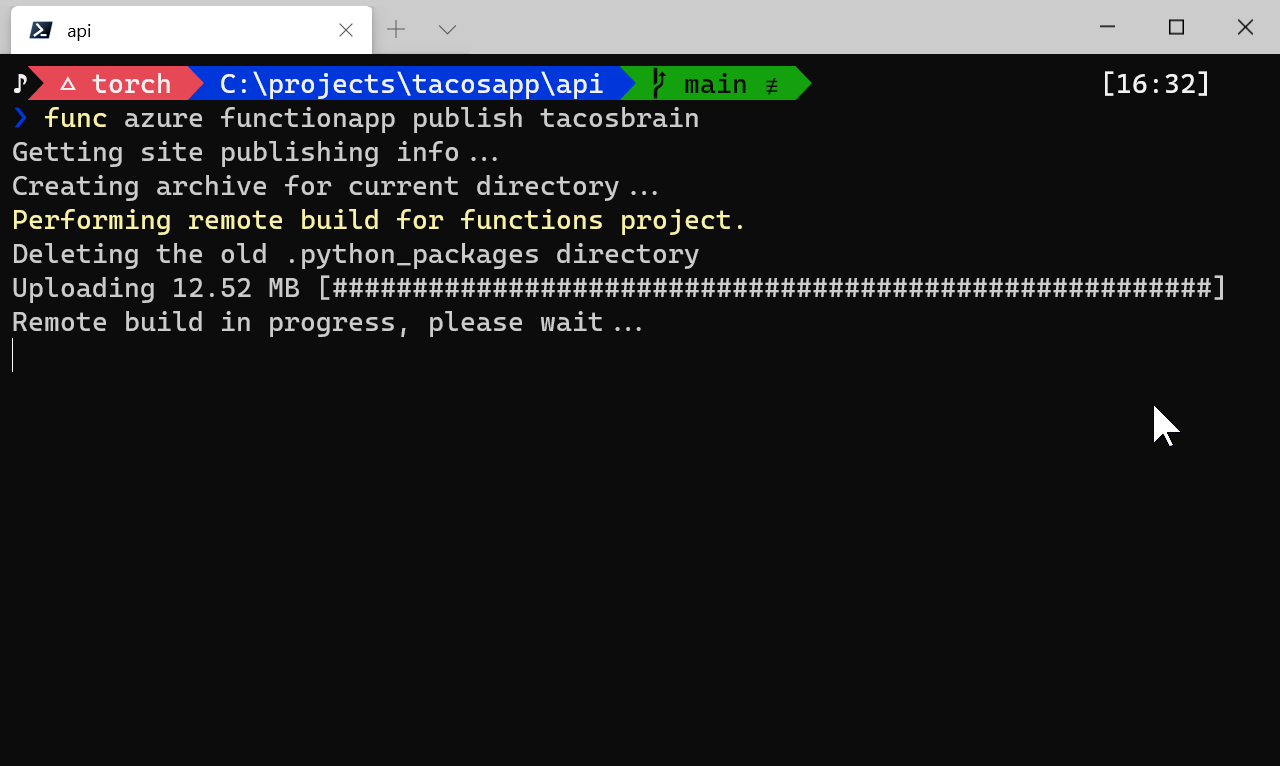
In my case it did not work:
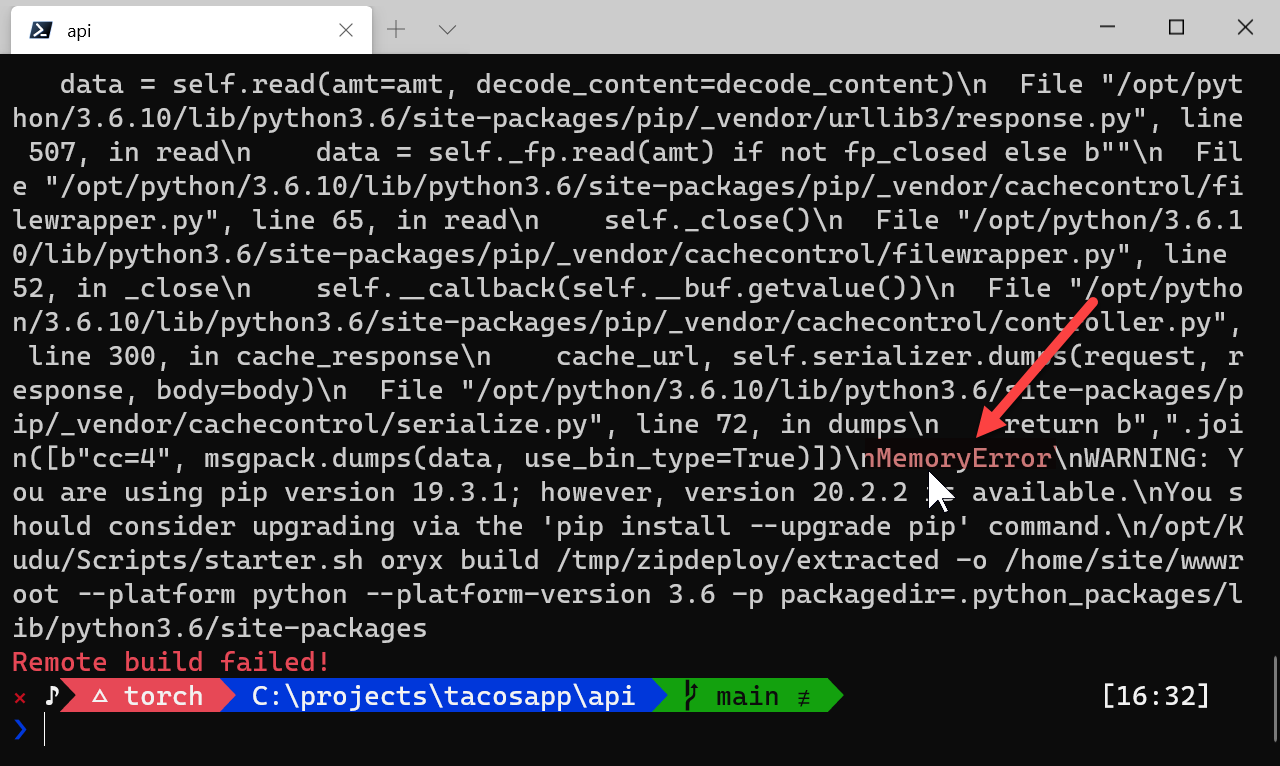
WHY????????? The answer is actually quite simple - in order to protect the remote environment some constraints are placed on how much space/memory/cpu et al is used to build the app. In my case there's a HUGE pip package that overflowed the memory (my bad). No worries though - there's other options!
Building Locally (First Try)
Turns out that running the func azure functionapp publish tacosbrain command is the same as
running func azure functionapp publish tacosbrain --build remote. AND theres a local option
as well:
func azure functionapp publish tacosbrain --build local
Since I have at my disposal the full power of my machine this should work!
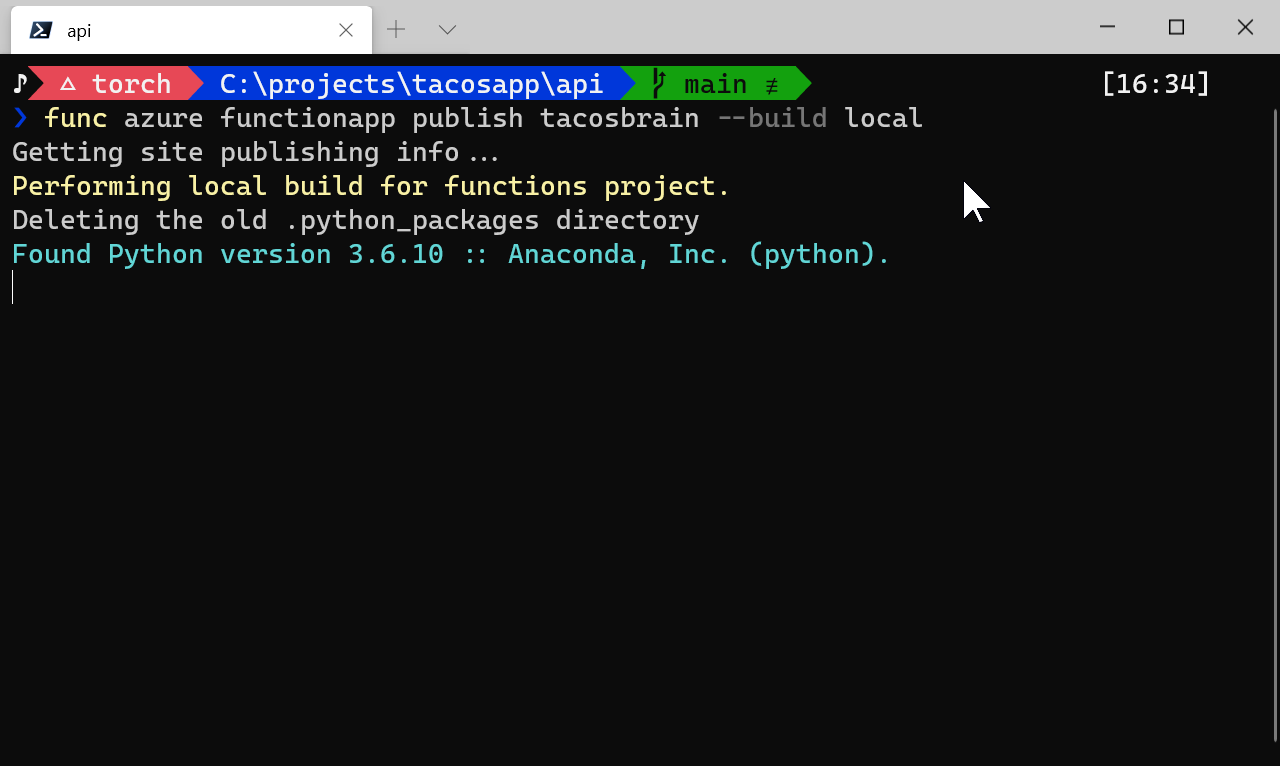
RIGHT?!?!!?
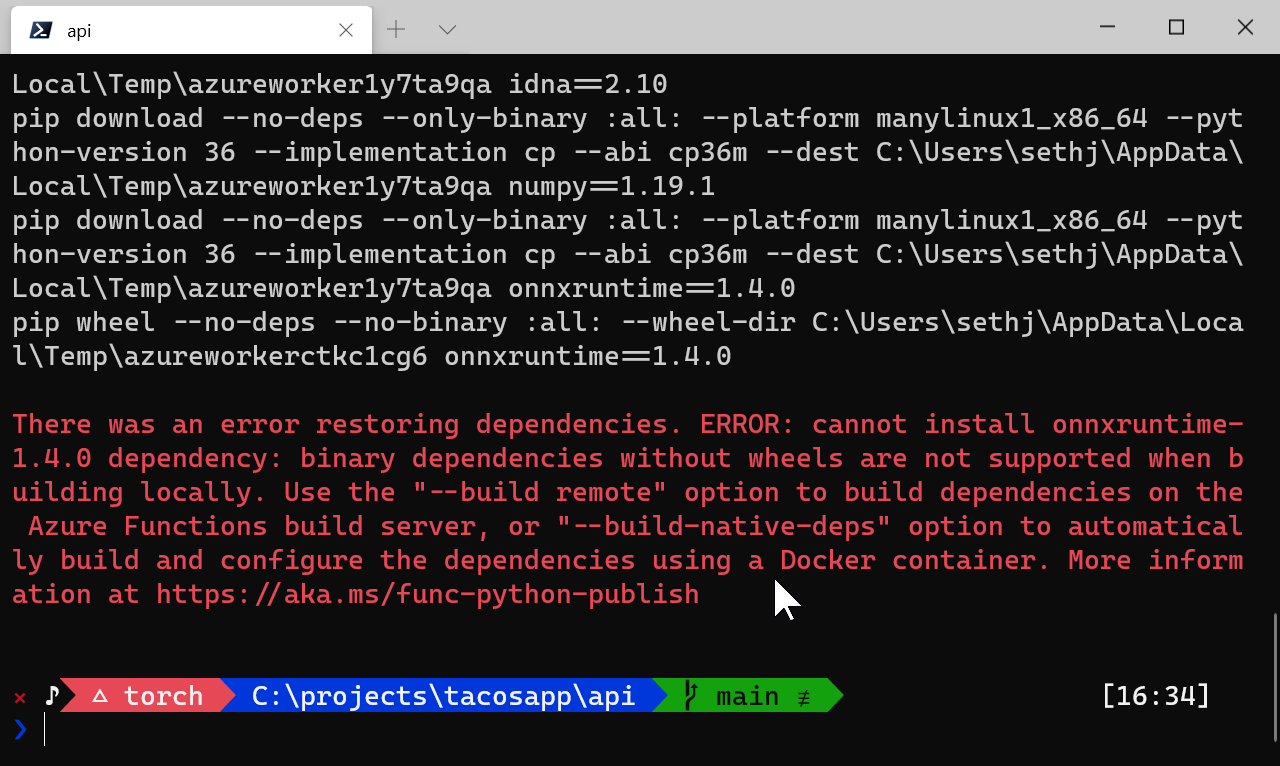
DOH! Strike two (#AMIRITE?????). There's also a simple answer to this problem as well.
Turns out that pip installing the onnxruntime on Windows just doesn't work (you have to
use conda in my case). How can we fix this?
Building Locally (with Native Deps)
The answer is always "use docker" (OK not always, but in this case it is). Turns out there's a way to deploy your Azure Function doing a local build with docker:
func azure functionapp publish tacosbrain --build local --build-native-deps
The key here is the --build-native-deps part:
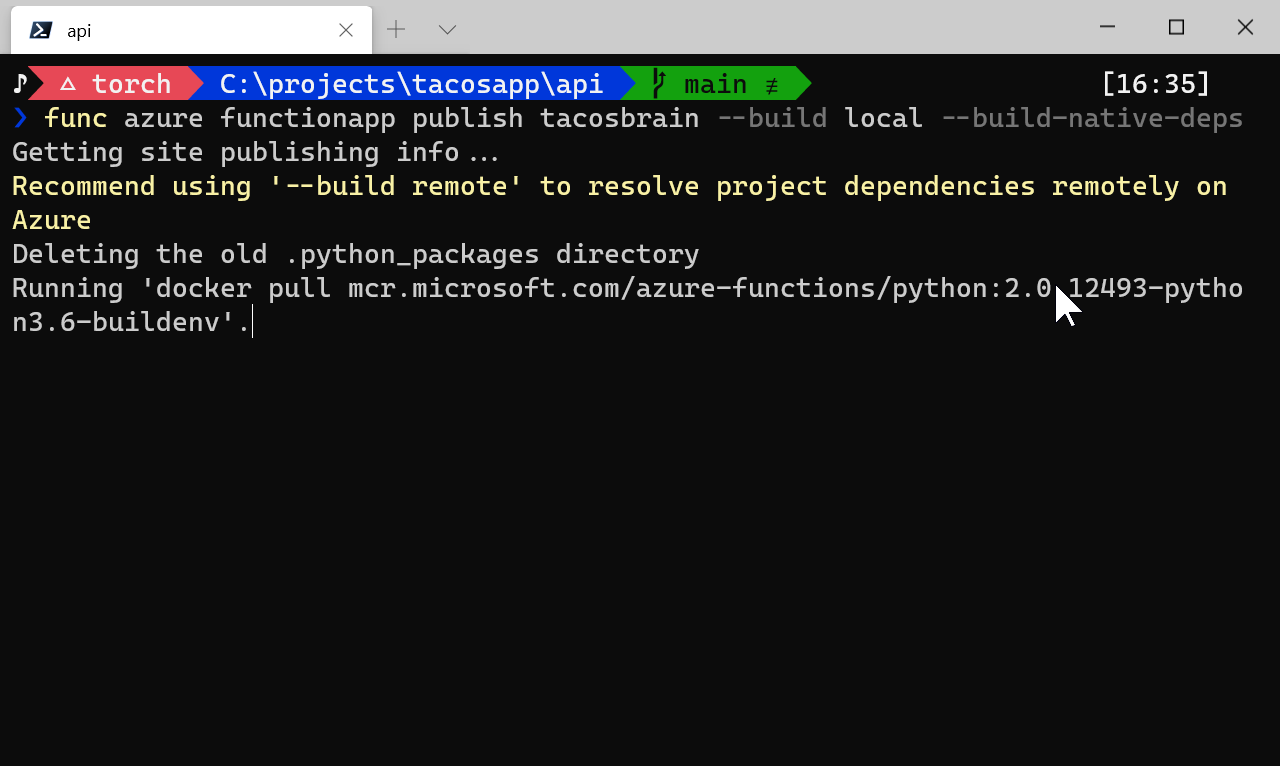
Notice how it pulls the appropriate docker file direct from Microsoft's docker registry! This process does take a bit longer but it works. Basically I get to be in control of what resources are used to build the deployment assets.
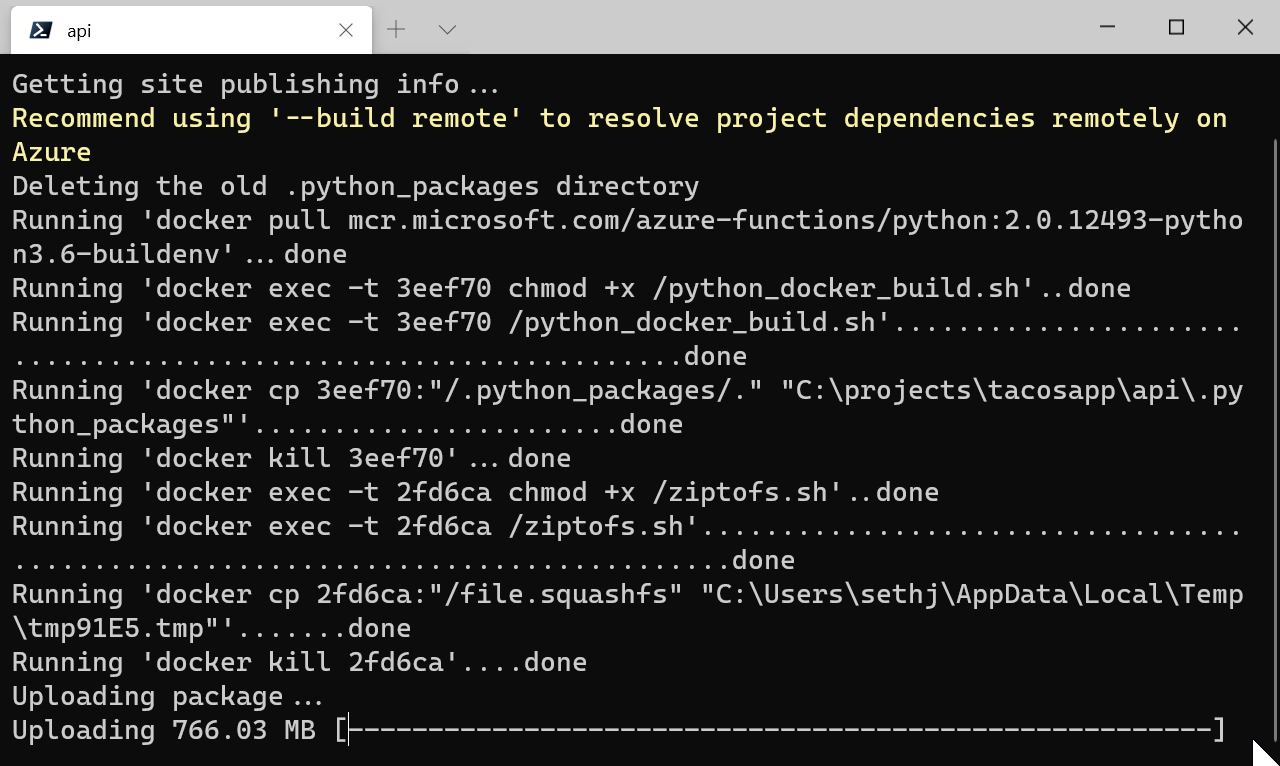
After some time - the build is done and pushed up! It is now ready to be called.
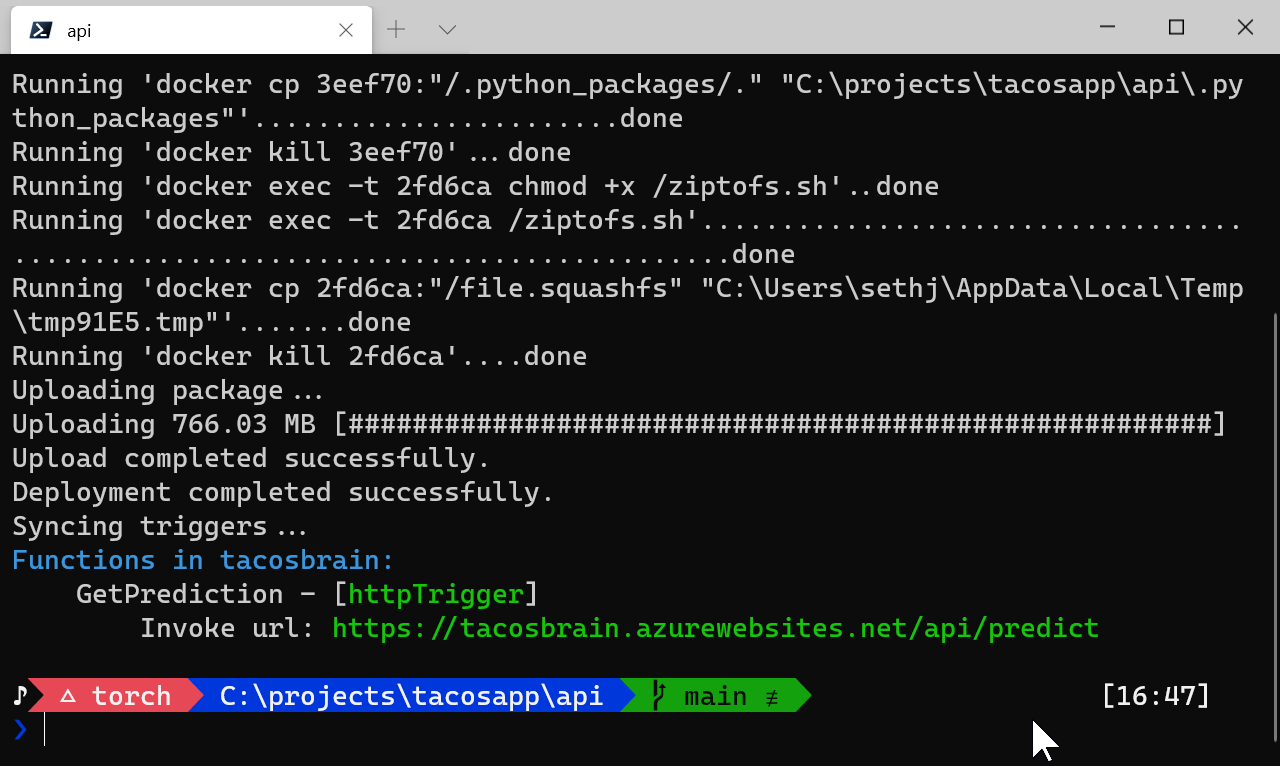
It even helpfully gives us the uri to call!
Why So Slow?
Let's curl it up!
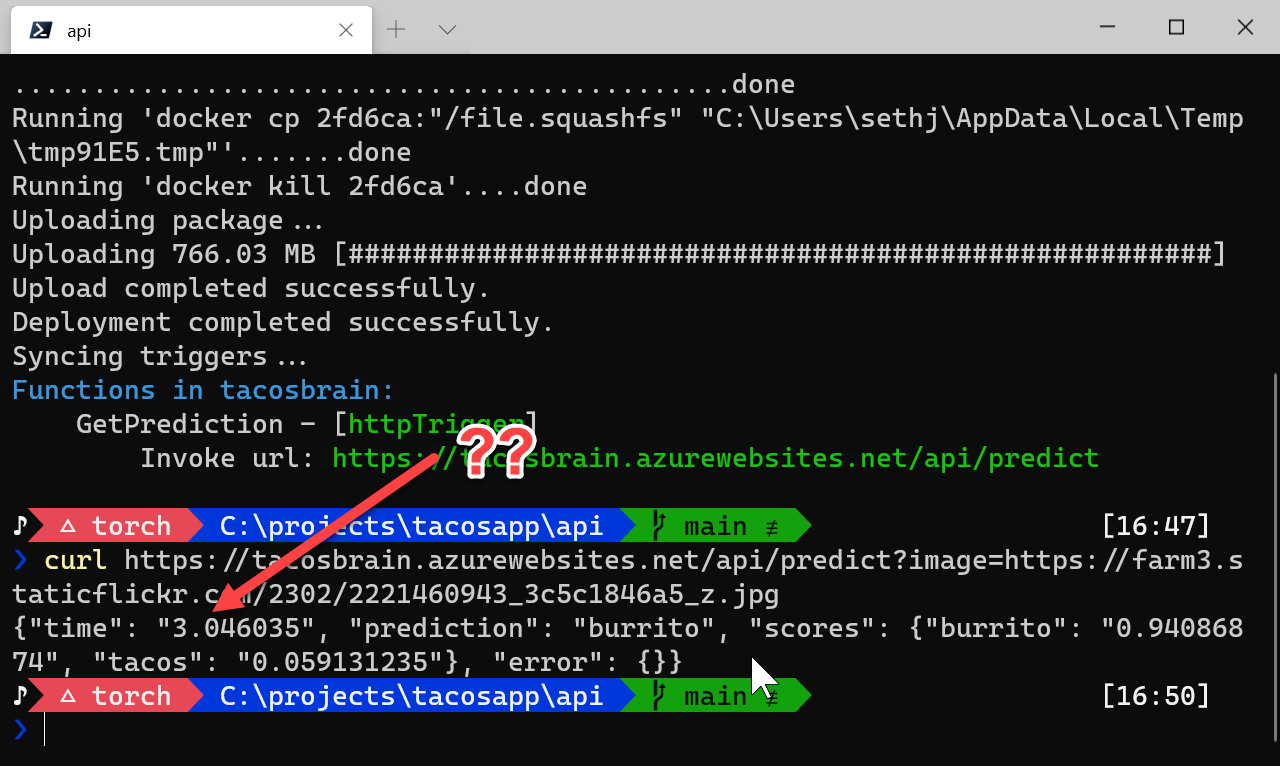
I know 3 seconds isn't a long time for regular people - it's ages for a computer though! Why is it so slow???? Turns out:
- It needs to warm up, and
- Load the model
#2 is what takes a while (I/O is finicky that way).
Better Warm
Here's what I did:
- I declared a set of
globalvariables that (if None) are initialized - I use the in memory objects
#1 only happens when it loads the first time.
...
global session, transform, classes, input_name
...
if session == None or transform == None or classes == None or input_name == None:
logging.info('=========================>Loading model, transorms and classes')
try:
model_path = os.path.join(context.function_directory, 'model.onnx')
classes = ['burrito', 'tacos']
session = rt.InferenceSession(model_path)
input_name = session.get_inputs()[0].name
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
except Exception as error:
logging.exception('Python Error')
response['error'] = {
'code': '500',
'message': f'{type(error).__name__}: {str(error)}'
}
...In this case the things we want in memory are session, transform, classes, and input_name since
they can easily be reused for each call. The second call to the API is much faster.
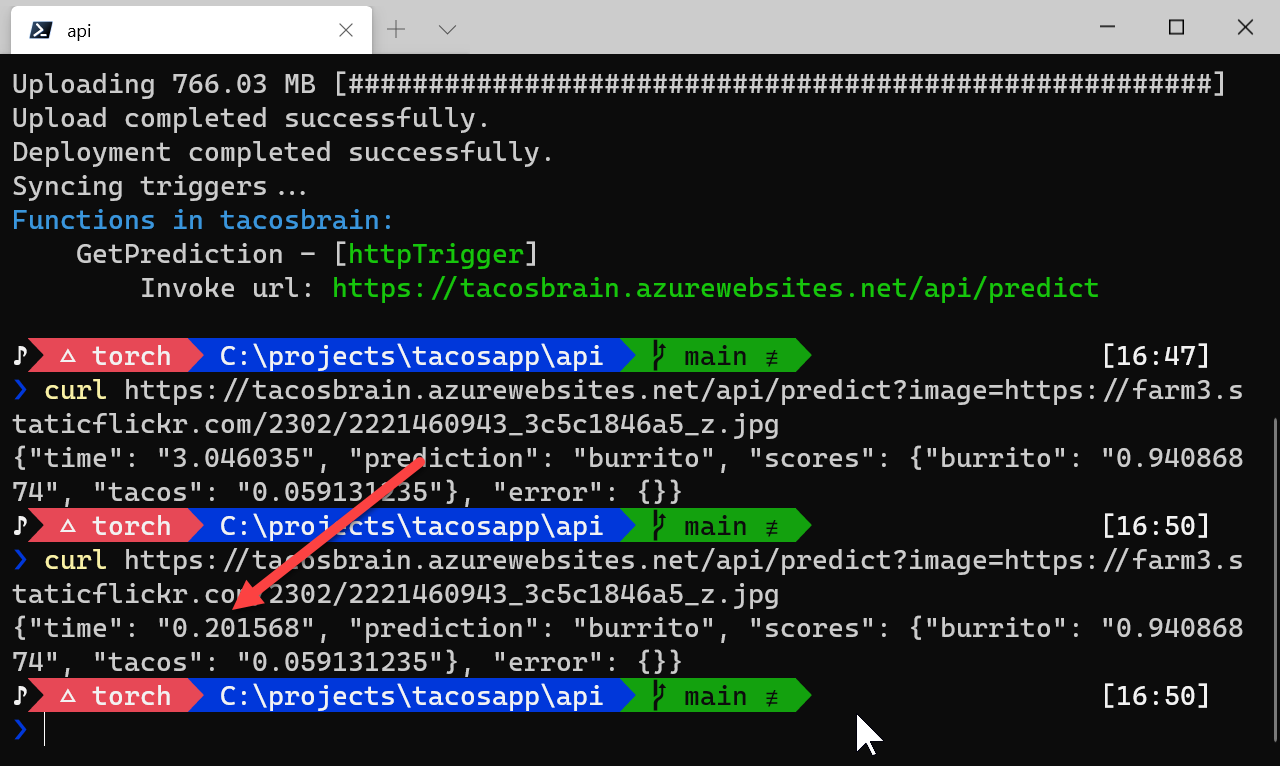
Keeping myself honest here:
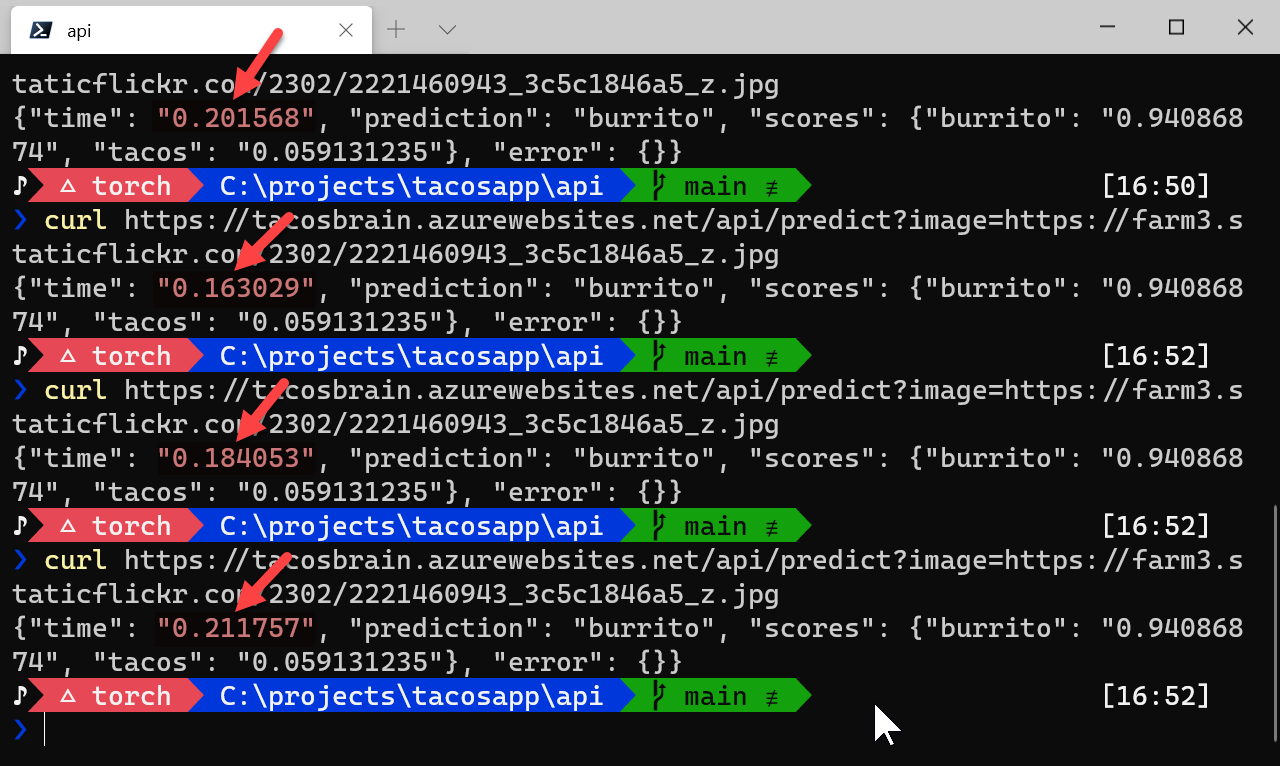
Every call after the first load is now much faster: exactly how we want it!
Review
To review:
- Make sure the Python versions match on your dev machine and the cloud
- Do a remote build first (this is by far the easiest thing to do)
- If a remote build fails, do a local build - you will control the computer resources used to create the appropriate artifacts
- If a standard local build fails (for whatever reason), use the
--build-native-depsflag to build locally in a container - If it still doesn't deploy correctly - wait, are you sure you got it to run locally?
Hope this helps!!! In the next couple of blog posts I will try to use the API in a client side app (stay tuned for that post)!!
Reference
Now for some helpful references:
- Tacos App on GitHub - this is still a work in progress (stay tuned)
- Azure Functions
- Working with the Azure Functions Core Tools
- Azure Functions Python developer guide
- Deploy Azure Functions in Python using Visual Studio Code